Системы искусственного интеллекта, предназначенные для диагностики рака по гистологическим препаратам, не демонстрируют одинаковой точности для всех пациентов, выявляя предвзятость в медицинских решениях. Ученые показали, что эту проблему можно существенно уменьшить за счет более продуманного обучения алгоритмов.
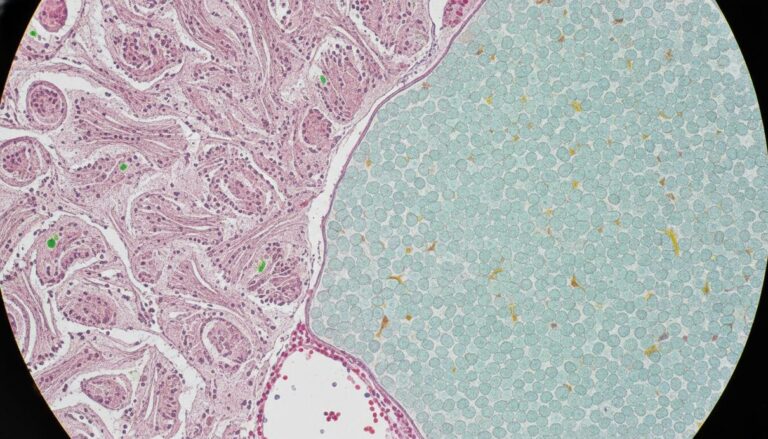
Десятилетиями патология играла ключевую роль в диагностике и лечении рака. Патолог исследует тончайший срез человеческой ткани под микроскопом, выявляя визуальные признаки наличия рака, его типа и стадии. Для опытного специалиста изучение образца ткани, испещренного клетками, подобно оценке теста без имени – слайд содержит жизненно важную информацию о болезни, но не дает никаких подсказок о пациенте.
Это предположение не в полной мере применимо к системам искусственного интеллекта, которые сейчас внедряются в патологоанатомические лаборатории. Новое исследование, проведенное учеными из Гарвардской медицинской школы, показало, что модели ИИ могут получать демографические данные непосредственно из гистологических препаратов. Эта неожиданная способность способна внести предвзятость в диагностику рака в различных группах пациентов.
Изучив несколько широко используемых моделей ИИ для выявления рака, исследователи обнаружили, что эти системы не работали одинаково для всех пациентов. Точность диагностики варьировалась в зависимости от самостоятельно сообщенных пациентами расы, пола и возраста. Команда также выявила несколько причин возникновения этих различий.
Для решения проблемы ученые разработали структуру под названием FAIR-Path, которая значительно уменьшила предвзятость в протестированных моделях. Кунь-Син Ю, старший автор исследования и доцент биомедицинской информатики в Институте Блаватника Гарвардской медицинской школы (HMS), а также доцент патологии в Бригхэмской и женской больнице, отмечает: «Чтение демографических данных с гистологического препарата считается «миссией невыполнимой» для патолога-человека, поэтому предвзятость в патологическом ИИ стала для нас неожиданностью».
Ю подчеркнул, что распознавание и исправление предвзятости в медицинском ИИ критически важно, поскольку это может напрямую влиять на точность диагностики и результаты лечения пациентов. Успех FAIR-Path предполагает, что улучшение справедливости в ИИ для онкологической патологии, и, возможно, в других медицинских инструментах ИИ, может не требовать серьезных изменений в существующих системах.
Исследование, частично поддержанное федеральным финансированием, было описано 16 декабря в журнале Cell Reports Medicine. Ю и его коллеги исследовали предвзятость в четырех широко используемых моделях патологического ИИ, разрабатываемых для диагностики рака. Эти системы глубокого обучения были обучены на больших коллекциях размеченных гистологических препаратов, что позволило им изучить биологические паттерны и применить эти знания к новым образцам.
Команда оценила модели, используя большой многоцентровой набор данных, который включал гистологические препараты 20 различных типов рака. Во всех четырех моделях постоянно выявлялись пробелы в производительности. Системы ИИ были менее точны для определенных демографических групп, определяемых расой, полом и возрастом. Например, модели с трудом различали подтипы рака легких у афроамериканских пациентов и у пациентов мужского пола. Также они показали снижение точности при классификации подтипов рака молочной железы у молодых пациентов. Кроме того, модели испытывали трудности с обнаружением рака молочной железы, почек, щитовидной железы и желудка в некоторых демографических группах. В целом, эти несоответствия проявлялись примерно в 29 процентах проанализированных диагностических задач.
По словам Ю, эти ошибки возникают потому, что системы ИИ извлекают демографическую информацию из изображений тканей, а затем полагаются на паттерны, связанные с этими демографическими данными, при принятии диагностических решений. Выводы оказались неожиданными. «Поскольку мы ожидали, что оценка патологии будет объективной, — отметил Ю. — При оценке изображений нам не обязательно знать демографические данные пациента для постановки диагноза». Это привело исследователей к ключевому вопросу: почему ИИ в патологии не соответствует тем же стандартам объективности?
Команда выявила три основных фактора, способствующих возникновению предвзятости. Во-первых, обучающие данные часто неравномерны. Образцы тканей легче получить от одних демографических групп, чем от других, что приводит к несбалансированным наборам данных. Это затрудняет точную диагностику рака моделями ИИ в группах, которые недопредставлены, включая некоторые популяции, определяемые расой, возрастом или полом. Однако, как отметил Ю, «проблема оказалась гораздо глубже». В ряде случаев модели работали хуже для определенных демографических групп даже при одинаковом размере выборки.
Дальнейший анализ указал на различия в заболеваемости. Некоторые виды рака встречаются чаще в определенных популяциях, что позволяет моделям ИИ быть особенно точными для этих групп. В результате те же модели могут испытывать трудности с диагностикой рака в популяциях, где эти заболевания менее распространены. Исследователи также обнаружили, что модели ИИ могут выявлять тонкие молекулярные различия между демографическими группами. Например, системы могут идентифицировать мутации в генах-драйверах рака и использовать их как «ярлыки» для классификации типа рака, что может снизить точность в популяциях, где эти мутации менее распространены.
«Мы обнаружили, что благодаря своей мощности ИИ может различать множество неочевидных биологических сигналов, которые не могут быть обнаружены стандартной человеческой оценкой», — утверждает Ю. Со временем это может привести к тому, что модели ИИ будут фокусироваться на сигналах, более тесно связанных с демографическими данными, чем с самой болезнью, ослабляя диагностическую производительность в разнообразных группах пациентов.
В совокупности, по словам Ю, эти выводы показывают, что предвзятость в патологическом ИИ обусловлена не только качеством и сбалансированностью обучающих данных, но и тем, как модели обучаются интерпретировать увиденное.
Выявив источники предвзятости, исследователи приступили к их устранению. Они разработали FAIR-Path – фреймворк, основанный на существующем методе машинного обучения, известном как контрастное обучение. Этот подход модифицирует обучение ИИ таким образом, чтобы модели сильнее фокусировались на критических различиях, например, между типами рака, при этом уменьшая внимание к менее релевантным различиям, включая демографические характеристики.
После применения FAIR-Path к протестированным моделям диагностические расхождения сократились примерно на 88 процентов. «Мы показали, что, внеся эту небольшую корректировку, модели могут изучать надежные признаки, которые делают их более обобщаемыми и справедливыми для разных популяций», — говорит Ю. Результат обнадеживает, добавил он, потому что он предполагает, что значительное снижение предвзятости возможно даже без идеально сбалансированных или полностью репрезентативных обучающих наборов данных.
В будущем Ю и его команда работают с учреждениями по всему миру, чтобы изучить предвзятость ИИ в патологии в регионах с различными демографическими данными, клинической практикой и лабораторными условиями. Они также исследуют, как FAIR-Path мог бы быть адаптирован для ситуаций с ограниченными данными. Еще одна область интересов – понимание того, как обусловленная ИИ предвзятость способствует более широким различиям в здравоохранении и результатах лечения пациентов.
Конечная цель, отмечает Ю, состоит в разработке систем ИИ для патологии, которые поддерживают специалистов-людей, обеспечивая быструю, точную и справедливую диагностику для всех пациентов. «Я думаю, есть надежда, что если мы будем более осведомлены и осторожны в том, как мы проектируем системы ИИ, мы сможем создавать модели, которые хорошо работают во всех популяциях», — заключил он.